Summarization
Contents
2.4. Summarization#
This section will cover a NLP task entitled Text Summarization. Text Summarization is the problem of reducing the number of sentences and/or words from a document, maintaining its original meaning.
There are multiple techniques to extract information. These techniques can be categorized as Extractive or Abstractive. Extractive techniques aim to retrieve the most important sentences from a document, without taking into consideration their meaning. Abstractive, on the other hand, use more complex and harder-to-train models to understand the semantics and meaning of the document text to create a proper summary.
2.4.1. LexRank#
LexRank [ER11] is an unsupervised Extractive summarization technique that uses a graph based approach for automatic text summarization. The score of each sentence is based on the concept of eigenvector centrality in a sentence’s graph representation.
This algorithm has a connectivity matrix based on intra-sentence cosine similarity, which is used as the adjacency matrix of the graph representation of sentences. In other words, sentences are placed as the graph vertices and the edges’ weights are calculated using cosine similarity.
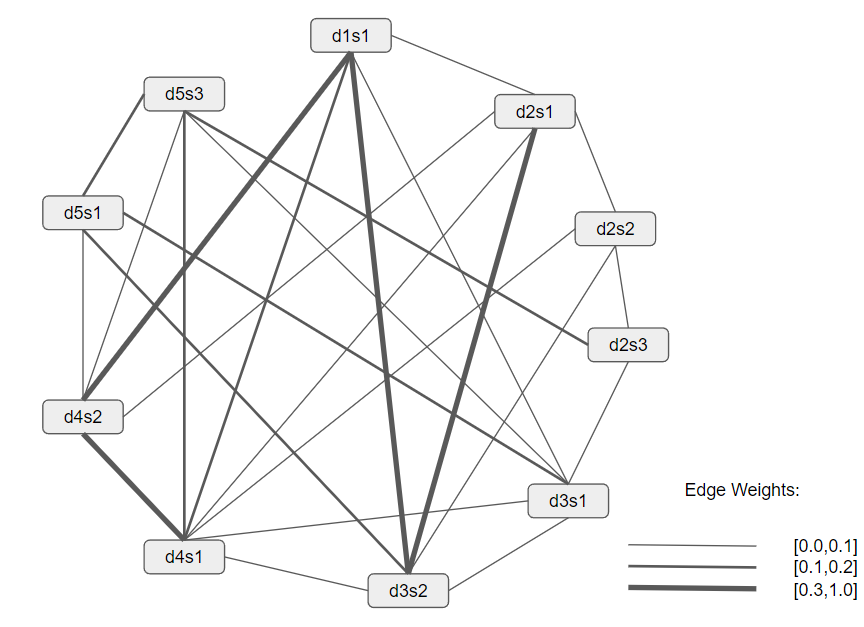
Figure based on [ER11]
2.4.1.1. Python usage#
"""
LexRank implementation
Source: https://github.com/crabcamp/lexrank/tree/dev
"""
import numpy as np
from scipy.sparse.csgraph import connected_components
from scipy.special import softmax
import logging
logger = logging.getLogger(__name__)
def degree_centrality_scores(
similarity_matrix,
threshold=None,
increase_power=True,
):
if not (
threshold is None
or isinstance(threshold, float)
and 0 <= threshold < 1
):
raise ValueError(
'\'threshold\' should be a floating-point number '
'from the interval [0, 1) or None',
)
if threshold is None:
markov_matrix = create_markov_matrix(similarity_matrix)
else:
markov_matrix = create_markov_matrix_discrete(
similarity_matrix,
threshold,
)
scores = stationary_distribution(
markov_matrix,
increase_power=increase_power,
normalized=False,
)
return scores
def _power_method(transition_matrix, increase_power=True, max_iter=10000):
eigenvector = np.ones(len(transition_matrix))
if len(eigenvector) == 1:
return eigenvector
transition = transition_matrix.transpose()
for _ in range(max_iter):
eigenvector_next = np.dot(transition, eigenvector)
if np.allclose(eigenvector_next, eigenvector):
return eigenvector_next
eigenvector = eigenvector_next
if increase_power:
transition = np.dot(transition, transition)
logger.warning("Maximum number of iterations for power method exceeded without convergence!")
return eigenvector_next
def connected_nodes(matrix):
_, labels = connected_components(matrix)
groups = []
for tag in np.unique(labels):
group = np.where(labels == tag)[0]
groups.append(group)
return groups
def create_markov_matrix(weights_matrix):
n_1, n_2 = weights_matrix.shape
if n_1 != n_2:
raise ValueError('\'weights_matrix\' should be square')
row_sum = weights_matrix.sum(axis=1, keepdims=True)
# normalize probability distribution differently if we have negative transition values
if np.min(weights_matrix) <= 0:
return softmax(weights_matrix, axis=1)
return weights_matrix / row_sum
def create_markov_matrix_discrete(weights_matrix, threshold):
discrete_weights_matrix = np.zeros(weights_matrix.shape)
ixs = np.where(weights_matrix >= threshold)
discrete_weights_matrix[ixs] = 1
return create_markov_matrix(discrete_weights_matrix)
def stationary_distribution(
transition_matrix,
increase_power=True,
normalized=True,
):
n_1, n_2 = transition_matrix.shape
if n_1 != n_2:
raise ValueError('\'transition_matrix\' should be square')
distribution = np.zeros(n_1)
grouped_indices = connected_nodes(transition_matrix)
for group in grouped_indices:
t_matrix = transition_matrix[np.ix_(group, group)]
eigenvector = _power_method(t_matrix, increase_power=increase_power)
distribution[group] = eigenvector
if normalized:
distribution /= n_1
return distribution
from sentence_transformers import SentenceTransformer, util
sentences = [
'One of David Cameron\'s closest friends and Conservative allies, '
'George Osborne rose rapidly after becoming MP for Tatton in 2001.',
'Michael Howard promoted him from shadow chief secretary to the '
'Treasury to shadow chancellor in May 2005, at the age of 34.',
'Mr Osborne took a key role in the election campaign and has been at '
'the forefront of the debate on how to deal with the recession and '
'the UK\'s spending deficit.',
'Even before Mr Cameron became leader the two were being likened to '
'Labour\'s Blair/Brown duo. The two have emulated them by becoming '
'prime minister and chancellor, but will want to avoid the spats.',
'Before entering Parliament, he was a special adviser in the '
'agriculture department when the Tories were in government and later '
'served as political secretary to William Hague.',
'The BBC understands that as chancellor, Mr Osborne, along with the '
'Treasury will retain responsibility for overseeing banks and '
'financial regulation.',
'Mr Osborne said the coalition government was planning to change the '
'tax system \"to make it fairer for people on low and middle '
'incomes\", and undertake \"long-term structural reform\" of the '
'banking sector, education and the welfare state.',
]
model = SentenceTransformer('neuralmind/bert-large-portuguese-cased')
#print("N sentences:", len(sentences))
#print(sentences)
#Compute the sentence embeddings
embeddings = model.encode(sentences, convert_to_tensor=True)
#Compute the pair-wise cosine similarities
cos_scores = util.cos_sim(embeddings, embeddings).numpy()
#Compute the centrality for each sentence
centrality_scores = degree_centrality_scores(cos_scores, threshold=None)
#We argsort so that the first element is the sentence with the highest score
most_central_sentence_indices = np.argsort(-centrality_scores)
#maximo random here
text = sentences[most_central_sentence_indices[0]]
print("Sentence with the highest centrality:\n",text)
No sentence-transformers model found with name C:\Users\Rui/.cache\torch\sentence_transformers\neuralmind_bert-large-portuguese-cased. Creating a new one with MEAN pooling.
Some weights of the model checkpoint at C:\Users\Rui/.cache\torch\sentence_transformers\neuralmind_bert-large-portuguese-cased were not used when initializing BertModel: ['cls.predictions.bias', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Sentence with the highest centrality:
Before entering Parliament, he was a special adviser in the agriculture department when the Tories were in government and later served as political secretary to William Hague.