Domain Adaptation
Contents
5.2. Domain Adaptation#
This section is still under construction.
Domain adaptation is a type of fine-tuning regarding language models. As the name suggests, the model can further understand a new domain. This scenario arises when a model is pre-trained on a specific dataset but needs to be utilised with a different (but related) dataset. In our context, BERTimbau was trained with a large Portuguese corpus, BrWaC, but we intended to use a model on Portuguese jurisprudence. Legal documents are similar to BrWaC since they share the same language. Nevertheless, documents provided by official courts should contain text better structured than BrWaC and contain some jargon and technical language inexistent otherwise. Over the years, multiple techniques have been aiming to adapt a language model to a new domain. This stage was done on the BERTimbau large variant, which can produce embeddings of 1024 dimensions. The Domain Adaptation stages were performed on a NVIDIA GeForce RTX 3090 24 GB GPU. The developed variants can be easily used with SentenceTransformers Python Library, TensorFlow, PyTorch, or JAX, since each model is hosted on the HuggingFace Platform, utilising the HuggingFace’s Transformers library.
5.2.1. Masked-Language-Model#
MLM, as mentioned previously, is a task originally introduced by BERT. The training consisted in applying the traditional BERT MLM training over our training dataset. With this approach, the model became more familiarized with technical language or jargon presented in those documents. For the MLM task, we defined the learning rate as 3e − 5. We want the learning rate in this stage to be significantly lower than in the initial training stage itself. Since we are training the model with numerous such parameters on a small dataset, it would easily overfit. With that same intention, the applied fine-tuning was done by performing only one epoch to reduce the probability of overfitting. This fine-tuning stage, performed with a batch size of 4, generated multiple BERTimbau variants. The loss associated with the training process can be shown in the following image:
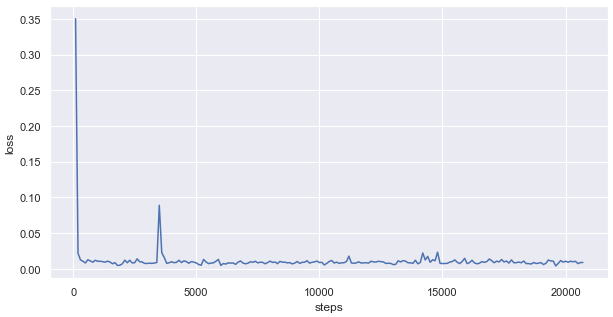
The selected MLM model variant was the one at 15000 training steps. The variant that was created is:
• stjiris/bert-large-portuguese-cased-legal-mlm-v0.11
https://huggingface.co/stjiris/bert-large-portuguese-cased-legal-mlm-v0.11
5.2.1.1. MLM code snippet#
5.2.1.1.1. Imports#
import torch
from tqdm.auto import tqdm
from transformers import AdamW
from transformers import BertTokenizer, BertForMaskedLM
import pandas as pd
#torch.cuda.set_device(1)
5.2.1.1.2. Load Model#
#Use original BERTimbau model
model_checkpoint = 'neuralmind/bert-large-portuguese-cased'
tokenizer = BertTokenizer.from_pretrained(model_checkpoint)
model = BertForMaskedLM.from_pretrained(model_checkpoint, return_dict=True)
Some weights of the model checkpoint at neuralmind/bert-large-portuguese-cased were not used when initializing BertForMaskedLM: ['cls.seq_relationship.bias', 'cls.seq_relationship.weight']
- This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
5.2.1.1.3. Read Data#
df2 = pd.read_csv('../Data/dadosLegais_all_cleaned.csv')
df2 = df2.iloc[: , 1]
df2 = df2.dropna()
AllSentencesForPreTraining2 = df2[:100].values.tolist()
print("Legal Data read")
Legal Data read
5.2.1.1.4. Tokenize#
inputs = tokenizer(
AllSentencesForPreTraining2,
max_length=512,
truncation=True,
padding='max_length',
return_tensors='pt'
)
print("inputs created")
inputs['labels'] = inputs['input_ids'].detach().clone()
random_tensor = torch.rand(inputs['input_ids'].shape)
# creating a mask tensor of float values ranging from 0 to 1 and avoiding special tokens
masked_tensor = (random_tensor < 0.15)*(inputs['input_ids'] != 101)*(inputs['input_ids'] != 102)*(inputs['input_ids'] != 0)
# getting all those indices from each row which are set to True, i.e. masked.
nonzeros_indices = []
for i in range(len(masked_tensor)):
nonzeros_indices.append(torch.flatten(masked_tensor[i].nonzero()).tolist())
# setting the values at those indices to be a MASK token (103) for every row in the original input_ids.
for i in range(len(inputs['input_ids'])):
inputs['input_ids'][i, nonzeros_indices[i]] = 103
inputs created
5.2.1.1.5. Create Dataloader#
class BookDataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __len__(self):
return len(self.encodings['input_ids'])
def __getitem__(self, index):
input_ids = self.encodings['input_ids'][index]
labels = self.encodings['labels'][index]
attention_mask = self.encodings['attention_mask'][index]
token_type_ids = self.encodings['token_type_ids'][index]
return {
'input_ids': input_ids,
'labels': labels,
'attention_mask': attention_mask,
'token_type_ids': token_type_ids
}
dataset = BookDataset(inputs)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=4,
shuffle=True
)
print("Dataloader created")
Dataloader created
5.2.1.1.6. Train#
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
epochs = 0
optimizer = AdamW(model.parameters(), lr=5e-5)
print("Started training")
model.train()
for epoch in range(epochs):
loop = tqdm(dataloader)
for batch in loop:
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
attention_mask = batch['attention_mask'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
loop.set_description("Epoch: {}".format(epoch))
loop.set_postfix(loss=loss.item())
Started training
C:\Users\Rui\anaconda3\lib\site-packages\transformers\optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
5.2.1.1.7. Save Model#
model.save_pretrained("TrainedModels/Legal_BERTimbau")
tokenizer.save_pretrained("TrainedModels/Legal_BERTimbau")
('TrainedModels/Legal_BERTimbau\\tokenizer_config.json',
'TrainedModels/Legal_BERTimbau\\special_tokens_map.json',
'TrainedModels/Legal_BERTimbau\\vocab.txt',
'TrainedModels/Legal_BERTimbau\\added_tokens.json')
5.2.2. TSDAE#
James Briggs -> https://www.pinecone.io/learn/unsupervised-training-sentence-transformers/
As described, TSDAE is an unsupervised sentence embedding approach. TSDAE encodes damaged sentences into fixed-sized vectors during training and needs the decoder to recover the original sentences from this sentence embedding. Later on, we employ the encoder to generate sentence embeddings during inference.
For the TSDAE task, we used a learning rate of 1e − 5 over our training dataset. The loss associated with the training process can be shown in the Figure.
The selected TSDAE model variant was the one at x training steps. The variant that was created is:
5.2.2.1. TSDAE code snippet#
5.2.2.1.1. Imports#
from sentence_transformers import SentenceTransformer, LoggingHandler
from sentence_transformers import models, util, datasets, evaluation, losses
from torch.utils.data import DataLoader
import pandas as pd
from sentence_transformers.datasets import DenoisingAutoEncoderDataset
from torch.utils.data import DataLoader
from sentence_transformers.losses import DenoisingAutoEncoderLoss
import torch
import nltk
#torch.cuda.set_device(1)
nltk.download('punkt')
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\Rui\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
True
5.2.2.1.2. Load Pre-trained Model#
Load BERTimbau model from HuggingFace Hub
# Define your sentence transformer model using CLS pooling
model_name = 'neuralmind/bert-large-portuguese-cased'
word_embedding_model = models.Transformer(model_name)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), 'cls')
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
Some weights of the model checkpoint at neuralmind/bert-large-portuguese-cased were not used when initializing BertModel: ['cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
5.2.2.1.3. Load Data from Documents#
Load Sentences and put them on a list
df2 = pd.read_csv("../Data/dadosLegais_all_cleaned.csv")
df2 = df2.iloc[: , 1]
df2 = df2.dropna()
#first 100 documents
train_sentences = df2[0:100].values.tolist()
5.2.2.1.4. Create Data Loader#
# dataset class with noise functionality built-in
train_data = DenoisingAutoEncoderDataset(train_sentences)
# we use a dataloader as usual
loader = DataLoader(train_data, batch_size=8, shuffle=True, drop_last=True)
loss = DenoisingAutoEncoderLoss(model, tie_encoder_decoder=True)
Some weights of the model checkpoint at neuralmind/bert-large-portuguese-cased were not used when initializing BertLMHeadModel: ['cls.seq_relationship.bias', 'cls.seq_relationship.weight']
- This IS expected if you are initializing BertLMHeadModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertLMHeadModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertLMHeadModel were not initialized from the model checkpoint at neuralmind/bert-large-portuguese-cased and are newly initialized: ['bert.encoder.layer.13.crossattention.self.key.bias', 'bert.encoder.layer.11.crossattention.self.key.weight', 'bert.encoder.layer.15.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.3.crossattention.self.value.weight', 'bert.encoder.layer.18.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.self.query.weight', 'bert.encoder.layer.22.crossattention.self.value.weight', 'bert.encoder.layer.15.crossattention.self.key.weight', 'bert.encoder.layer.2.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.9.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.self.value.bias', 'bert.encoder.layer.22.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.23.crossattention.self.query.bias', 'bert.encoder.layer.15.crossattention.self.value.weight', 'bert.encoder.layer.1.crossattention.self.value.bias', 'bert.encoder.layer.20.crossattention.self.key.bias', 'bert.encoder.layer.5.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.8.crossattention.self.query.weight', 'bert.encoder.layer.7.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.self.key.bias', 'bert.encoder.layer.15.crossattention.self.key.bias', 'bert.encoder.layer.21.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.21.crossattention.self.query.weight', 'bert.encoder.layer.6.crossattention.output.dense.weight', 'bert.encoder.layer.8.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.21.crossattention.self.query.bias', 'bert.encoder.layer.9.crossattention.output.dense.weight', 'bert.encoder.layer.5.crossattention.self.key.weight', 'bert.encoder.layer.14.crossattention.self.key.weight', 'bert.encoder.layer.18.crossattention.self.key.bias', 'bert.encoder.layer.12.crossattention.self.key.bias', 'bert.encoder.layer.15.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.17.crossattention.self.key.weight', 'bert.encoder.layer.0.crossattention.self.query.bias', 'bert.encoder.layer.12.crossattention.self.query.weight', 'bert.encoder.layer.10.crossattention.self.value.weight', 'bert.encoder.layer.18.crossattention.self.key.weight', 'bert.encoder.layer.23.crossattention.self.key.weight', 'bert.encoder.layer.1.crossattention.output.dense.weight', 'bert.encoder.layer.8.crossattention.output.dense.bias', 'bert.encoder.layer.4.crossattention.output.dense.bias', 'bert.encoder.layer.16.crossattention.output.dense.bias', 'bert.encoder.layer.22.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.11.crossattention.self.key.bias', 'bert.encoder.layer.15.crossattention.self.value.bias', 'bert.encoder.layer.9.crossattention.self.value.weight', 'bert.encoder.layer.11.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.self.query.weight', 'bert.encoder.layer.12.crossattention.output.dense.weight', 'bert.encoder.layer.3.crossattention.self.key.weight', 'bert.encoder.layer.13.crossattention.self.query.weight', 'bert.encoder.layer.13.crossattention.self.value.bias', 'bert.encoder.layer.5.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.15.crossattention.output.dense.bias', 'bert.encoder.layer.2.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.7.crossattention.self.key.bias', 'bert.encoder.layer.1.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.19.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.10.crossattention.output.dense.bias', 'bert.encoder.layer.23.crossattention.self.key.bias', 'bert.encoder.layer.9.crossattention.self.query.bias', 'bert.encoder.layer.14.crossattention.output.dense.weight', 'bert.encoder.layer.0.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.20.crossattention.self.query.bias', 'bert.encoder.layer.16.crossattention.self.query.weight', 'bert.encoder.layer.13.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.22.crossattention.self.key.weight', 'bert.encoder.layer.16.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.self.query.bias', 'bert.encoder.layer.0.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.2.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.self.key.bias', 'bert.encoder.layer.17.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.20.crossattention.self.value.weight', 'bert.encoder.layer.18.crossattention.output.dense.weight', 'bert.encoder.layer.4.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.4.crossattention.output.dense.weight', 'bert.encoder.layer.11.crossattention.self.query.bias', 'bert.encoder.layer.18.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.3.crossattention.output.dense.bias', 'bert.encoder.layer.8.crossattention.self.key.weight', 'bert.encoder.layer.14.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.3.crossattention.self.key.bias', 'bert.encoder.layer.16.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.output.dense.weight', 'bert.encoder.layer.15.crossattention.self.query.bias', 'bert.encoder.layer.21.crossattention.self.key.weight', 'bert.encoder.layer.3.crossattention.self.query.bias', 'bert.encoder.layer.14.crossattention.self.value.bias', 'bert.encoder.layer.2.crossattention.self.query.bias', 'bert.encoder.layer.19.crossattention.self.value.bias', 'bert.encoder.layer.13.crossattention.self.key.weight', 'bert.encoder.layer.17.crossattention.self.query.bias', 'bert.encoder.layer.19.crossattention.self.key.bias', 'bert.encoder.layer.22.crossattention.self.query.weight', 'bert.encoder.layer.2.crossattention.self.query.weight', 'bert.encoder.layer.1.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.self.query.bias', 'bert.encoder.layer.20.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.self.value.weight', 'bert.encoder.layer.4.crossattention.self.value.weight', 'bert.encoder.layer.23.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.23.crossattention.self.value.bias', 'bert.encoder.layer.17.crossattention.self.key.bias', 'bert.encoder.layer.4.crossattention.self.key.weight', 'bert.encoder.layer.1.crossattention.self.key.weight', 'bert.encoder.layer.0.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.self.key.weight', 'bert.encoder.layer.9.crossattention.self.key.bias', 'bert.encoder.layer.21.crossattention.output.dense.weight', 'bert.encoder.layer.13.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.self.query.weight', 'bert.encoder.layer.20.crossattention.self.key.weight', 'bert.encoder.layer.23.crossattention.output.dense.bias', 'bert.encoder.layer.13.crossattention.output.dense.weight', 'bert.encoder.layer.5.crossattention.self.key.bias', 'bert.encoder.layer.21.crossattention.self.key.bias', 'bert.encoder.layer.14.crossattention.self.key.bias', 'bert.encoder.layer.14.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.15.crossattention.output.dense.weight', 'bert.encoder.layer.23.crossattention.self.value.weight', 'bert.encoder.layer.6.crossattention.self.key.bias', 'bert.encoder.layer.9.crossattention.self.value.bias', 'bert.encoder.layer.14.crossattention.self.query.bias', 'bert.encoder.layer.11.crossattention.self.query.weight', 'bert.encoder.layer.17.crossattention.self.query.weight', 'bert.encoder.layer.17.crossattention.output.dense.weight', 'bert.encoder.layer.3.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.4.crossattention.self.query.bias', 'bert.encoder.layer.22.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.self.query.weight', 'bert.encoder.layer.8.crossattention.self.key.bias', 'bert.encoder.layer.10.crossattention.self.query.weight', 'bert.encoder.layer.20.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.0.crossattention.self.query.weight', 'bert.encoder.layer.21.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.5.crossattention.self.value.bias', 'bert.encoder.layer.7.crossattention.self.value.bias', 'bert.encoder.layer.10.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.output.dense.weight', 'bert.encoder.layer.6.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.self.key.bias', 'bert.encoder.layer.9.crossattention.self.query.weight', 'bert.encoder.layer.22.crossattention.self.key.bias', 'bert.encoder.layer.16.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.1.crossattention.self.value.weight', 'bert.encoder.layer.2.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.self.value.weight', 'bert.encoder.layer.16.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.8.crossattention.output.dense.weight', 'bert.encoder.layer.15.crossattention.self.query.weight', 'bert.encoder.layer.18.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.12.crossattention.output.dense.bias', 'bert.encoder.layer.3.crossattention.self.value.bias', 'bert.encoder.layer.7.crossattention.self.query.weight', 'bert.encoder.layer.18.crossattention.output.dense.bias', 'bert.encoder.layer.20.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.13.crossattention.self.value.weight', 'bert.encoder.layer.19.crossattention.output.dense.bias', 'bert.encoder.layer.11.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.self.query.bias', 'bert.encoder.layer.23.crossattention.self.query.weight', 'bert.encoder.layer.9.crossattention.output.dense.bias', 'bert.encoder.layer.19.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.18.crossattention.self.value.bias', 'bert.encoder.layer.6.crossattention.self.key.weight', 'bert.encoder.layer.1.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.21.crossattention.output.dense.bias', 'bert.encoder.layer.7.crossattention.output.dense.weight', 'bert.encoder.layer.8.crossattention.self.query.bias', 'bert.encoder.layer.7.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.17.crossattention.self.value.bias', 'bert.encoder.layer.22.crossattention.output.dense.bias', 'bert.encoder.layer.11.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.17.crossattention.output.dense.bias', 'bert.encoder.layer.12.crossattention.self.value.weight', 'bert.encoder.layer.13.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.self.value.bias', 'bert.encoder.layer.5.crossattention.output.dense.weight', 'bert.encoder.layer.13.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.self.value.weight', 'bert.encoder.layer.8.crossattention.self.value.weight', 'bert.encoder.layer.16.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.self.value.bias', 'bert.encoder.layer.16.crossattention.self.key.bias', 'bert.encoder.layer.11.crossattention.self.value.bias', 'bert.encoder.layer.20.crossattention.output.dense.bias', 'bert.encoder.layer.16.crossattention.self.query.bias', 'bert.encoder.layer.18.crossattention.self.query.bias', 'bert.encoder.layer.21.crossattention.self.value.weight', 'bert.encoder.layer.10.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.6.crossattention.self.query.bias', 'bert.encoder.layer.14.crossattention.self.query.weight', 'bert.encoder.layer.4.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.10.crossattention.output.dense.weight', 'bert.encoder.layer.0.crossattention.self.key.weight', 'bert.encoder.layer.19.crossattention.self.key.weight', 'bert.encoder.layer.17.crossattention.self.value.weight', 'bert.encoder.layer.20.crossattention.self.query.weight', 'bert.encoder.layer.9.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.16.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.12.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.2.crossattention.self.key.weight', 'bert.encoder.layer.14.crossattention.output.dense.bias', 'bert.encoder.layer.12.crossattention.self.query.bias', 'bert.encoder.layer.12.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.22.crossattention.self.query.bias', 'bert.encoder.layer.4.crossattention.self.key.bias', 'bert.encoder.layer.9.crossattention.self.key.weight', 'bert.encoder.layer.21.crossattention.self.value.bias', 'bert.encoder.layer.19.crossattention.self.query.weight', 'bert.encoder.layer.7.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.2.crossattention.self.value.weight', 'bert.encoder.layer.18.crossattention.self.value.weight', 'bert.encoder.layer.23.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.self.query.weight', 'bert.encoder.layer.19.crossattention.output.dense.weight', 'bert.encoder.layer.6.crossattention.self.value.bias', 'bert.encoder.layer.12.crossattention.self.key.weight', 'bert.encoder.layer.23.crossattention.output.dense.weight', 'bert.encoder.layer.12.crossattention.self.value.bias', 'bert.encoder.layer.20.crossattention.output.dense.weight', 'bert.encoder.layer.11.crossattention.output.dense.weight', 'bert.encoder.layer.14.crossattention.self.value.weight', 'bert.encoder.layer.1.crossattention.self.key.bias', 'bert.encoder.layer.22.crossattention.output.dense.weight', 'bert.encoder.layer.7.crossattention.self.key.weight', 'bert.encoder.layer.11.crossattention.self.value.weight', 'bert.encoder.layer.19.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.output.dense.bias', 'bert.encoder.layer.17.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.19.crossattention.self.query.bias', 'bert.encoder.layer.8.crossattention.self.value.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
The following encoder weights were not tied to the decoder ['bert/pooler']
5.2.2.1.5. Train#
model.fit(
train_objectives=[(loader, loss)],
epochs=0,
weight_decay=0,
scheduler='constantlr',
optimizer_params={'lr': 3e-5},
show_progress_bar=True
)
model.save('output/tsdae-bert-base-uncased')
a = model.encode("O advogado apresentou as provas ao juíz.")
b = model.encode("O juíz leu as provas.")
c = model.encode("O juíz leu o recurso.")
d = model.encode("O juíz atirou uma pedra.")
# Compute cosine-similarits matrix
cosine_scores = util.pytorch_cos_sim(a, b)
print("Cosine-Similarity:", cosine_scores)
cosine_scores = util.pytorch_cos_sim(a, c)
print("Cosine-Similarity:", cosine_scores)
cosine_scores = util.pytorch_cos_sim(a, d)
print("Cosine-Similarity:", cosine_scores)
Cosine-Similarity: tensor([[0.9642]])
Cosine-Similarity: tensor([[0.9488]])
Cosine-Similarity: tensor([[0.9188]])
5.2.3. Generative Pseudo Labeling#
GPL, is a state-of-the-art unsupervised technique to fine-tune existing models in different domain. This technique allows a model to understand which sentences can answer a question.
As explained, GPL has three different stages: Query Generation (from GenQ), Negative Mining and Pseudo Labeling.
In the Query Generation step, we created 10000 Queries for 10000 legal documents. We used a pre-trained T5 model, fine-tuned for the Portuguese Language, pierreguillou/t5-base-qa-squad-v1.1- portuguese26, to generate queries from each document summary. After this step, we have a collection of queries that each summary (positive passage) should be able to answer individually.
In the Negative Mining stage, we retrieved passages very similar to our initial passage but should not be able to answer the generated queries. For this purpose, we created an index on ElasticSearch where we stored the embeddings of the other summaries utilised for the previous step. To reduce the bias in the system, we utilised an original BERTimbau large fine-tuned for STS. This model was fine-tuned following the guidelines in the original paper. We used assin and assin2 datasets for five epochs, using 3e − 5 for the learning rate.
In the final step, we utilised the same model to calculate the margin between positive and negative passages using the dot product. We train our models with the created trip lets (positive passage, negative passage and margin score), applying the Margin Mean Squared Error Loss with a learning rate of 2e − 5 on one epoch.
5.2.4. Training Datasets#
The training dataset used for these stages is available on HuggingFace Hub, at https://huggingface.co/datasets/rufimelo/PortugueseLegalSentences-v0, https://huggingface.co/datasets/stjiris/portuguese-legal-sentences-v0 and https://huggingface.co/datasets/stjiris/IRIS_sts_legal_dataset