Semantic Search Type
4.2. Semantic Search Type#
Semantic search aims to improve the overall search quality by understanding the underlining query and sentences meaning. It achieves that by creating embeddings, which are vectorial representations of words, paragraphs, or even documents into a vector space. Both queries and sentences are embedded into the same vector space, and the closest embeddings is found.

There are two types of semantic search:
Symmetric semantic search
Asymmetric semantic search
Symmetric semantic search systemaims to match a query input with text. For instance, if a user inputs in the search system “What are the consequences of robbing?”, it should be expected to receive retrievals with “What are the laws that involves robbing?”. In practice, both query and result should have similar length.
Asymmetric semantic search, on the other hand, provides answers to questions. Usually, the query is short, and it expects a larger paragraph to be returned. A user might search “What are the consequences of robbing?”, and it is expected to retrieve a sentence similar to “The consequences of robbing are various from case to case. First, we need to identify the object or quantity being stolen…”
We chose to implement a symmetric semantic search system. The reasoning behind such decision was specially due to the lack of queries and results pairs examples to implement a proper asymmetric semantic search. On the same note, when a judge interacts with a search system, the judge is more likely to insert an extensive query with proper terminology, than inputting a question that wants to be answered.
When applying a Symmetric semantic search, there are two approaches:
Bi-Encoders
Cross-Encoders
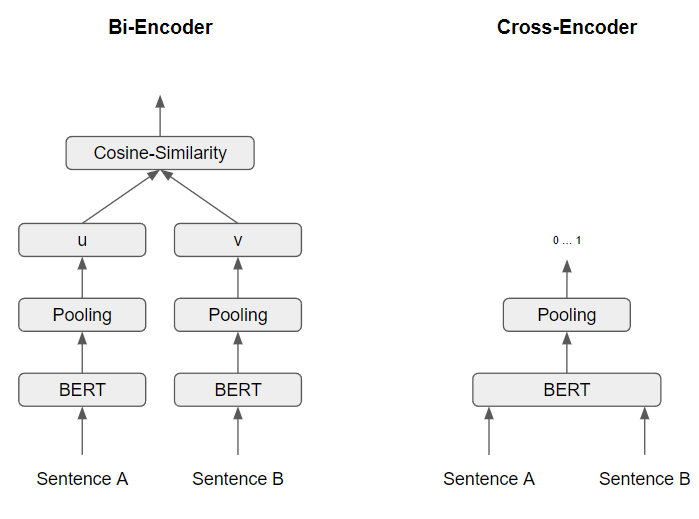
Figure based on https://www.sbert.net/examples/applications/cross-encoder/README.html
Bi-Encoders produce for a given sentence a sentence embedding. Using SBERT, we embed sentences \(A\) and \(B\) independently, producing the sentence embeddings \(u\) and \(v\), respectively. These sentence embedding can be later compared using cosine similarity.
Cross-Encoders, on the other hand, receives both sentences \(A\) and \(B\) at the same time and outputs a value between \(0\) and \(1\), representing the similarity of those sentences. Cross-Encoders does not return a sentence embedding. It only compares the similarity between two sentences, which always need to be passed simultaneously.
In our scenario, with over 30000 documents, the solution was to implement a Bi-Encoder. We needed to create the embeddings independently of each other, allowing to search later using the cosine similarity. This way, the overall search system performance is doable, whereas if we utilise a Cross-Encoder, the search would not be feasible.