BERT
Contents
3.1. BERT#
Bidirectional Encoder Representations from Transformers (BERT) is a model proposed by researchers at Google AI Language in 2019 [DCLT19]. Just like humans tend to understand a word based on its context, and its surroundings, BERT aims to do exactly that. Traditionally, models would look at text sequences from left to right or vice-versa. BERT is trained bidirectionally in order to obtain a higher level of understanding of the language, making use of the Transformers architecture. It makes use of two phases: pre-training and fine-tuning.
The problem that emerges when applying bidirectional unsupervised training is the trivial prediction of words. In unidirectional training, words can only see their left or right context. It is the existence of direction in the training that allows for an unbiased prediction of each next word. When that does not exist, as is the case in bidirectional training, the prediction of each word — based on both its left and right words — becomes biased, and words are then able to predict themselves.
One of the tasks of using language models is to predict the next word in a sentence. BERT aims to not only be able to predict that but also to, effectively, understand the language. However, this process, done trivially, would produce a biased model, since it makes use of a certain direction. To tackle this phenomenon and reduce the bias, the original paper used 2 techniques in the pre-training phase while using BooksCorpus (800M words) and English Wikipedia (2500M words) as the datasets:
Masked-Language Modeling (MLM)
Next Sentence Prediction (NSP)
MLM is a technique that revolves around applying a [MASK] token to words, so their prediction can be less biased. In the original paper, in a normal pre-training cycle, 15% of the words in each sequence are selected for a masking treatment. The model then aims to predict some masked words based on the surrounding unmasked words. The words that are selected for the masking treatment were not treated the same way. 80% of the selected words are replaced with a [MASK] token. 10% of the selected words are replaced with a random token, and the remaining 10% just keep the original token.
NSP is a task in which the model aims to understand sentence relationships. There are a lot of applications like Question and Answer (QA) and Natural Language Inference (NLI) that revolves around this sense of understanding. In the BERT training process, BERT receives multiple pairs of sentences as input. It proceeds to predict if the second sentence is a subsequent sentence of the first one. In this training process, 50% of the inputs are indeed subsequent statements, and are deemed positive (labelled as IsNext), and the other 50% are deemed negative (labelled as NotNext), meaning that the second sentence is completely disconnected from the first one. In order to represent the input words as scalar vectors that are able to be read, BERT creates word embeddings based on three components. The first component is the Token Embedding Layer, which is responsible for assigning a value to each word. The second layer is the Segmentation Embedding Layer which allows for the determination of whether a word belongs to sentence A or B. The third component is the Position Embedding Layer which is responsible for modelling how a token at one position affects another token at a different position.
In the second phase, fine-tuning, one additional layer is added after the final BERT layer and the entire network is trained for a few epochs with the Adam Optimizer.
With this architecture, two model sizes were reported: \(BERT_{BASE}\) and \(BERT_{LARGE}\). They have sizes \(L=12\), \(H=768\), \(A=12\) with \(Total Parameters=110M\) and \(L=24\), \(H=1024\), \(A=16\) with \(Total Parameters=340M\), where \(L\) represents the number of layers, \(H\) the hidden size, and \(A\) the number of self-attention heads. The results in this paper demonstrate a solid performance.
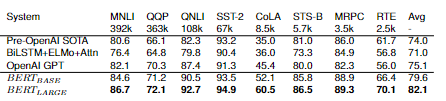
Figure retrieved from [VSP+17]
DistilBERT is a modification of BERT that contains 40% less parameters than \(BERT_{BASE}\), runs 60% faster with a performance close to 95% of the original BERT model (according to the GLUE language benchmark).
3.1.1. Domain Adaptation#
NNs require significant amounts of data for proper training, especially labelled data. Usually, such large quantities of data are unavailable and training deep learning models can be very time-consuming, often requiring specialized and expensive hardware. Deep learning models can perform well on a specific test dataset from the same domain as the training dataset. However, they tend to be less efficient with dataset from different domains.
Task data consists of an observable task distribution. Usually non-randomly sampled from a wider distribution within an even larger target domain. This target domain might be excluded from the original pretraining domain. [GMS+20]
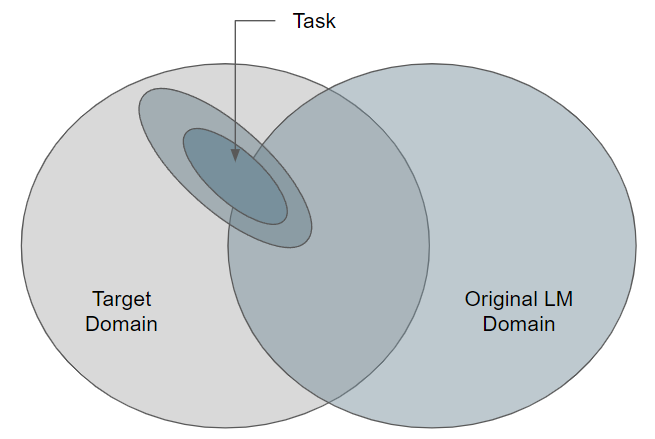 Figure based on [GMS+20]
Figure based on [GMS+20]
Domain Adaptation (DA) is a technique that aims to tackle this issue. With this technique, a model should perform on a new dataset that comes from a different domain similarly to as it would on the testing dataset. Usually, in order to achieve this type of result, deep learning models are re-trained on unsupervised learning tasks. DA saves large amounts of computational resources and, by utilizing unsupervised learning methods, reduces the necessity of manual annotation of labelled datasets.
This subsection will cover multiple DA techniques that can be utilized for BERT models.
3.1.1.1. Masked Language Modeling#
MLM, as mentioned previously, is a task originally introduced by BERT. Words, selected at random with a 15% chance, are masked from the input sentence with a predefined probability (80%) and the model aims to predict those masked words.
To apply MLM with the intent of adapting the domain a model performs in, usually, the model is re-trained over 1 epoch on a new dataset. The learning rate utilized is the same or slightly lower than the MLM task performed on the model pre-training. The reasoning behind such choice is to slightly change on the weights used on the NN, without destabilizing the network completely.
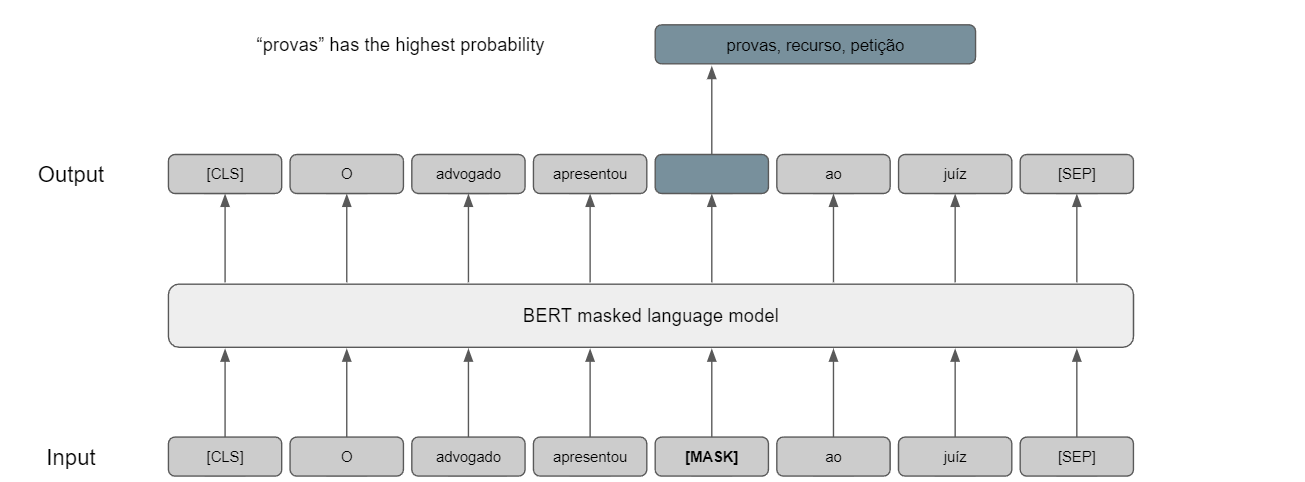 Figure based on https://www.sbert.net/examples/unsupervised_learning/MLM/README.html
Figure based on https://www.sbert.net/examples/unsupervised_learning/MLM/README.html
3.1.1.2. Constrative Tension#
In the Semantic Re-tuning with Contrastive Tension (CT) paper [CGG+21], published in 2020, Carlsson et al. presented unsupervised method entitled CT. In their research, they found that similar sentences tend to have a low cosine similarity score.
They decided to train two encoder models, equally initialized, simultaneously. The two embedding spaces would initially be the same. They trained the models to maximize the dot product of identical sentences while reducing the dot product of different sentences.
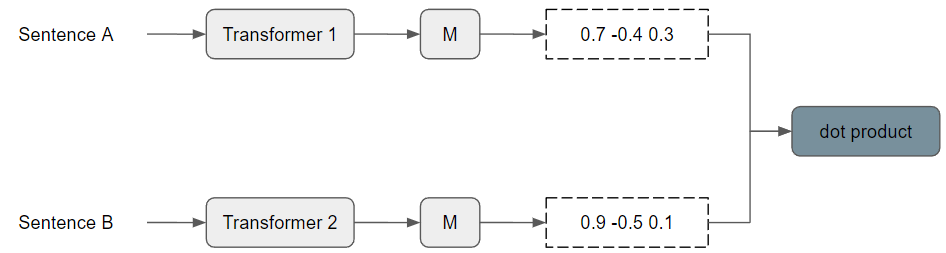 Figure based on [CGG+21]
Figure based on [CGG+21]
3.1.1.3. SimCSE#
In 2021, Gao et al. presented imple Contrastive Learning of Sentence Embeddings (SimCSE) [GYC21]. This unsupervised method had the reasoning stated in 2006 by Hadsell et al.[HCL06] to pull close neighbours together and push apart other non-neighbours. This contrastive learning makes use of the InfoNCE loss, defined in the equation.
where \(sim()\) represents the similarity function, \(h_i\) represents the sentence embeddings and \(T\) represents the Temperature. \(e^{sim(h_i, h_i^+)/T}\) and \(e^{sim(h_i, h_j^+)/T}\) represent positive and negative pairs, respectively. Positive pairs are embeddings of the same sentence, but with different standard dropout masks. Due to the drop-out, the embeddings will be encoded at slightly different positions in the vector space. On the other hand, negative pairs are embeddings of other sentences from the same batch (in-batch negatives). The distance between these two embeddings will be minimized, while the distance to other embeddings of the same batch’s sentences will be maximized. SimCSE architecture is shown in the Figure.
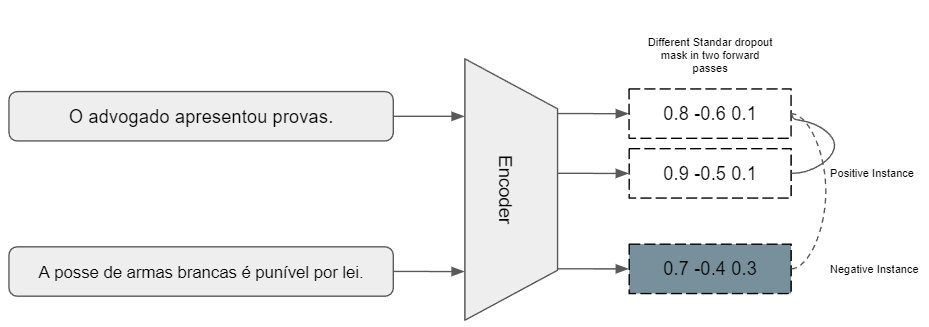 Figure based on [GYC21]
Figure based on [GYC21]
3.1.1.4. BERT-flow#
“Pre-trained contextual representations like BERT have achieved great success in natural language processing. However, the sentence embeddings from the pre-trained language models without fine-tuning have been found to poorly capture semantic meaning of sentences. In this paper, we argue that the semantic information in the BERT embeddings is not fully exploited. We first reveal the theoretical connection between the masked language model pre-training objective and the semantic similarity task theoretically, and then analyze the BERT sentence embeddings empirically. We find that BERT always induces a non-smooth anisotropic semantic space of sentences, which harms its performance of semantic similarity. To address this issue, we propose to transform the anisotropic sentence embedding distribution to a smooth and isotropic Gaussian distribution through normalizing flows that are learned with an unsupervised objective. Experimental results show that our proposed BERT-flow method obtains significant performance gains over the state-of-the-art sentence embeddings on a variety of semantic textual similarity tasks. The code is available at this https URL.” [LZH+20]
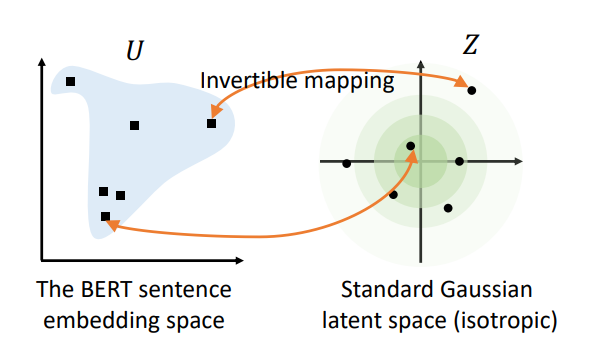 Figure retrieved from [LZH+20]
Figure retrieved from [LZH+20]
3.1.1.5. Transformer-based Sequential Denoising Auto-Encoder#
Transformer-based Sequential Denoising Auto-Encoder (TSDAE) is an unsupervised state-of-the-art sentence embedding method based on pre-trained TSDAE which outperforms previous approaches, such as MLM. Firstly published on April 14th of 2021 by Nils Reimers [WRG21], this technique aims to improve the domain knowledge of a model. They state that TSDAE fills the gap between models that usually only perform the Semantic Textual Similarity (STS) task on a certain domain. TSDAE’s model architecture is a modified encoder-decoder Transformer, with the key and value of the cross-attention mechanism limited to the sentence embedding.
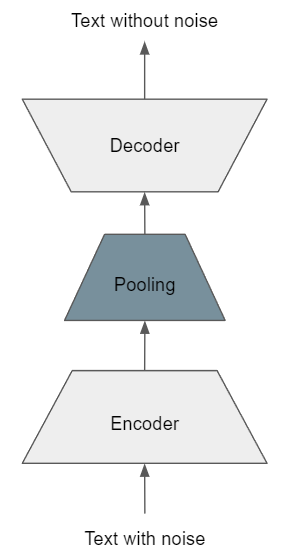
Figure based on [WRG21]
In a sense it is similar to MLM, but instead of swapping words for [MASK] tokens, TSDAE introduces noise to the sentences by deleting or swapping words. The encoder transforms the sentence into a vector, and a decoder is supposed to reconstruct the original sentence. Formally, the training objective is shown in the equation.
where \(D\) is our training corpus, \(x = x_1 x_2 ... x_l\) is the input sentence with \(l\) tokens, \(x_)\) is the corresponding damaged sentence. \(e_t\) is the word embedding of \(x_t\), and \(h_t\) represents the hidden state at decoding step \(t\).
We can then utilize the encoder to generate sentence embeddings during inference.
3.1.1.6. GenQ#
GenQ [TRRuckle+21], published in October 2021 by the Ubiquitous Knowledge Processing Lab team, is an unsupervised domain adaptation method for dense retrieval models. In the paper BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models GenQ was proposed, which allowed generating queries from given passages. This approach aims for a semantic search system to be asymmetric (explored in subsection 4.2), supporting question-answering scenarios simply by training with synthetically generated data.
Firstly, GenQ requires a Text-to-Text Transfer Transformer (T5) model fine-tuned for question-answering. In the original paper, they fine-tuned a T5 (base) model on MS MARCO for two epochs. After that, it utilised the T5 model to generate queries from original passages. The idea behind T5 models is that all NLP tasks can be defined as a text-to-text problem, so they are trained on numerous tasks with immense amounts of data. One of these tasks is query generation. By feeding a passage, T5 models can generate multiple questions that the passage may answer. These generated queries might be far from ideal. The T5 model used is one for general purposes, which can lead to noisy data with plenty of randomnesses. Thus, a dense model, such as SBERT, can be fine-tuned with the passages and synthetically generated query pairs using the Multiple Negatives Ranking (MNR) loss.
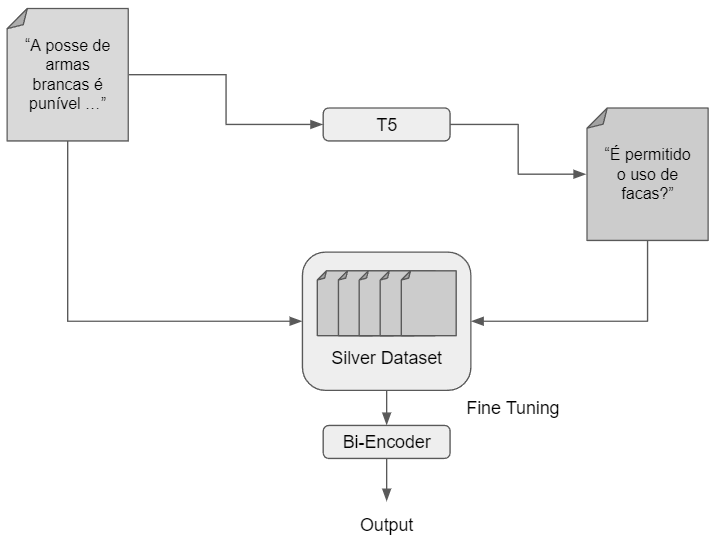
Figure based on [TRRuckle+21]
3.1.1.7. Generative Pseudo-Labeling#
Generative Pseudo-Labeling (GPL), published in December 2021 in the paper GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval [WTRG21], is a improved state-of-the-art technique to perform domain adaptation of dense models.
It is composed of three phases, as shown in the next Figure. Firstly, there is a Query Generation step, where it is used the GenQ approach to generate queries for multiple passages. At this point, we have access to queries and passages, which can be called positive passages since they are passages that could answer the generated queries.
Secondly, there is a Negative Mining step. Negative mining is a technique to retrieve passages that would not answer the previously generated queries. Nevertheless, these negative passages are similar to the positive passages in the vector space. In practice, a dense index would be filled with multiple passages, and the closest ones to the positive passages would be retrieved and noted as negative passages.
The last and fundamental step is called Pseudo Labeling. In this step, a Cross-Encoder receives the triplets composed of a query, a positive, and a negative passage. The Cross-Encoder calculates the score margin between the negative and positive passages. The training model will use the Margin MSE Loss, to identify whether these passages are also relevant to the given query.
The loss function is calculated based on the \(sim(Query, Pos) - sim(Query, Neg)|\) and \(|gold_sim(Q, Pos) - gold_sim(Query, Neg)|\). It was used the dot product as default for calculating the similarity between passages and queries, as stated in the original paper.
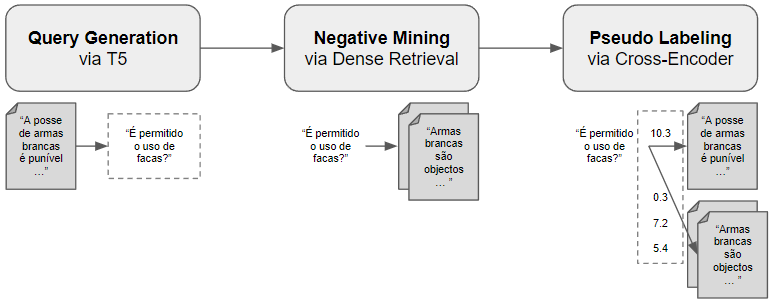
Figure based on [WTRG21]
3.1.2. Fine-tuning on Downstream Tasks#
3.1.2.1. Sentence-BERT#
There was a need for representing an entire sentence in an embedding, instead of only one word or token. One implementation was using the BERT model on all the tokens present in a sentence and producing a mean pooling. Even though this technique was fast enough for the desired problem, it was not very accurate (GloVe embeddings, designed in 2014 produced better results than this technique).
Sentence-BERT (SBERT) [RG19], implemented in 2019 by a group of researchers from the Ubiquitous Knowledge Processing (UKP) lab, is a modification of the BERT network using siamese and triplet networks which can create sentence embeddings that are semantic meaningful. This modification of BERT allows for new types of tasks, such as semantic similarity comparison or information retrieval via semantic search.
Reimers and Gurevych showed that SBERT is dramatically faster than BERT to compare sentence pairs. From 10 000 Sentences it took BERT 65 hours to find the most similar sentence, while SBERT produced the embeddings in approximately 5 seconds and, using the cosine similarity, it took approximately 0.01 seconds.
The siamese architecture is composed of two BERT models that have weights entangled between them. In the training process, the sentences would be fed to both BERT models, which then would go through a pooling operation that would transform the token embeddings of size \(512 \times 768\) into a vector of a fixed size of \(768\).
One way of fine-tuning SBERT is through the Softmax loss approach. It used a combination of the Stanford Natural Language Inference (SNLI) [SNL] and the Multi-Genre NLI [Mul] datasets. The datasets contained pairs of sentences (premises and hypothesis) that could be related through a label feature. This label feature determined whether the sentences are related or not.
“entailment”, the premise suggests the hypothesis
“neutral”, the premise and hypothesis could not be related
“contradiction”, the premise and hypothesis contradict each other
This type of fine-tuning aims to train the model to identify the relationship between sentences.
Another task that SBERT can be fine-tuned is the Semantic Textual Similarity (STS) task. The siamese architecture calculates the cosine similarity between \(u\) and \(v\) sentence embeddings. The researchers also tried negative Manhattan and negative Euclidean distances as similarity measures, but the results were similar. The model performance evaluation, in terms of Semantic Textual Similarity, was evaluated on Supervised and Unsupervised Learning.
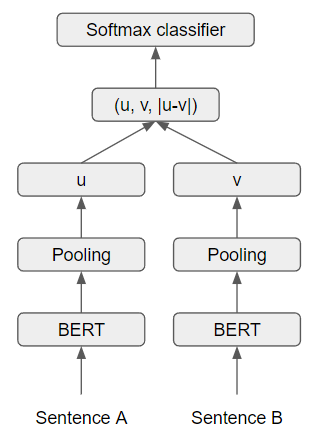
Figure based on [RG19]
Regarding the Unsupervised Learning, the researchers used the STS tasks 2012 – 2016 by Agirre et al. [Agia] [Agib] [Agic] [Agid] [Agie], the STS benchmark by Cer et al. [Cer] and the SICK-Relatedness dataset [Mar]. Each of these three datasets contained gold labels between 0 and 5 that reflects how similar each sentence pair is. Tableshows the Spearman correlation \(\rho\) between the cosine similarity of sentence representations and the gold labels for various Textual Similarity (STS) tasks. The performance is reported by convention as \(\rho\) x 100.
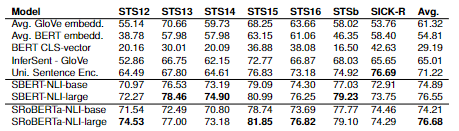
Figure retrieved from [RG19]
To evaluate Supervised learning, the researchers chose to fine-tune \ac{SBERT} only with the \ac{STS} benchmark (STSb), which is “a popular dataset to evaluate supervised \ac{STS} systems” (Reimers et al. 2019) and first train on \ac{NLI} and then on STSb.
To evaluate Supervised learning, the researchers chose to fine-tune SBERT only with the STS benchmark (STSb), which is “a popular dataset to evaluate supervised STS systems” (Reimers et al. 2019) and first train on NLI and then on STSb.
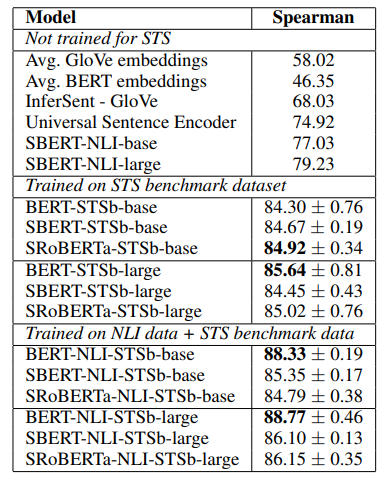
Figure retrieved from [RG19]
3.1.2.2. Multilingual Sentence Embeddings#
One issue raised by using pre-trained models is that the embeddings models are usually monolingual, since they are usually trained in English. In 2020, the lead researcher from the team that published SBERT, introduced a technique called multilingual knowledge distillation [RG20]. It relies on the premises that for a set of parallel sentences \(((s_1, t_1), ...,(s_n, t_n))\) with \(t_i\) being the translation of \(s_i\) and a teacher Model \(M\), a Model \(\hat{M}\) would produce vectors for both \(s_i\) and \(t_i\) close to the teacher Model \(M\) sentence vectors. For a given batch of sentences \(\beta\), they minimize the mean-squared loss as follows:
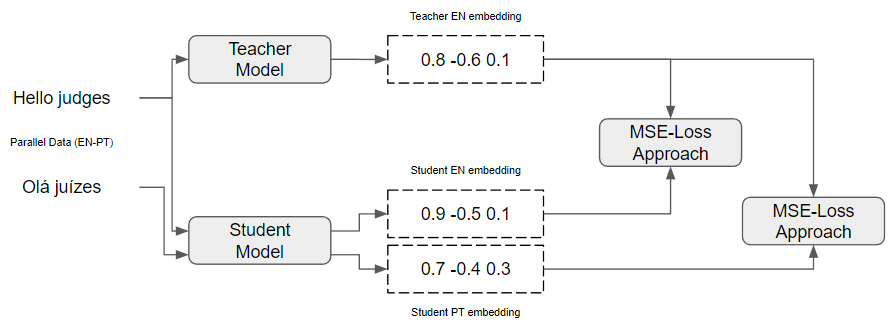
Figure based on [RG20]
Multilingual SBERT versions, such as paraphrase-multilingual-mpnet-base (768 Dimensions) or paraphrase-multilingual-MiniLM-L12 (384 Dimensions) would provide relatively accurate embeddings to this context. The mpnet model, as a larger model than MiniLM, should be able to better comprehend the meaning of a text that it hasn’t explicitly seen before, such as queries with only 1 or 2 words.
3.1.2.3. Named-Entity Recognition#
[TODO]
Named-Entity Recognition (NER) is a task that aims to identify and classify named entities in a text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
3.1.2.4. Question-Answering#
[TODO]
Question-answer (QA) systems are a type of information retrieval system that, given a question, searches for an answer in a collection of texts. The QA systems can be divided into two categories: open-domain and closed-domain. The open-domain QA systems are able to answer questions about any topic, while the closed-domain QA systems are limited to a specific domain.
???