Metadata Knowledge Distillation
5.6. Metadata Knowledge Distillation#
This work presents a new technique developed to improve information retrieval through dense vectors: Metadata Knowledge Distillation.
In our dataset, multiple documents have associated with them “Descritores”, brief tags manually annotated by experts. These tags intend to identify the main document subjects. These tags could indicate if a crime was committed with knives or even if it is related to COVID-19.
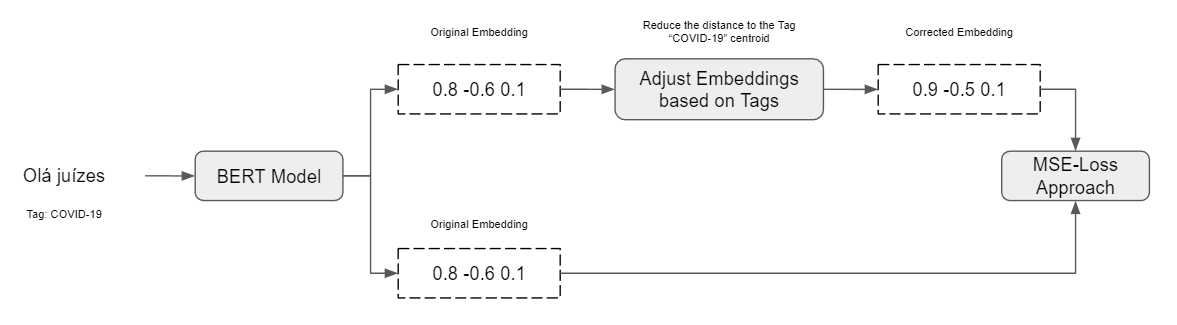
With such annotation, we assumed that the documents are, in a way, related to one another. Thus, the sentences from each document have some trim level of entailment between each other. We started by identifying the documents related to a subject, COVID-19, i.e. and we processed to encode those documents’ sentences. The generated embeddings form a cluster. We processed to calculate the centroid of those embeddings and adjusted the embeddings slightly to the centroid. (1-5%) This minor adjustment is based on the assumption that those sentences are related and, thus, they should be closer to one another. This process is done through the tags we have available. This ideologycan be shown in the following Figure
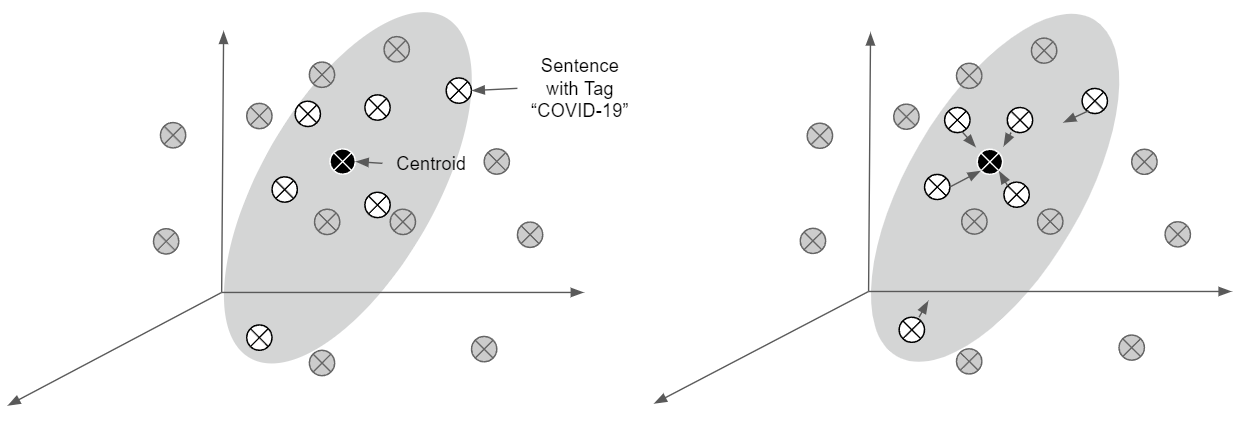
Finally, the updated embeddings will serve as gold labels for what the embeddings of the same model should look like. We then applied the mean-squared error loss, similar to Multilingual Knowledge Distillation, to train the model.