Architecture
Contents
4.3. Architecture#
4.3.1. Semantic Search System#
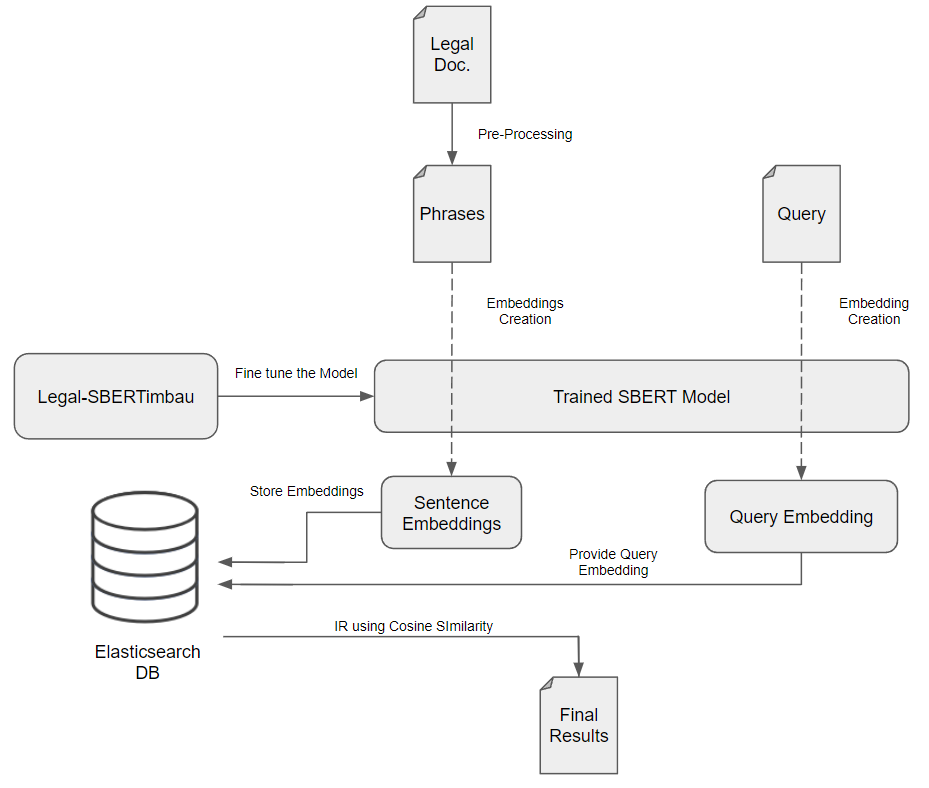
Initially, there was a pre-processing of the documents in the original dataset to split the entire documents into smaller units. This pre-processing was essential to separate the text into smaller passages, since Legal-BERTimbau would be less effective on large sentences. Nevertheless, it was required to analyse the documents in more detail to verify if the phrases are too long, too short or if they raised other concerns, such as referenced in Data Preparation. On the other hand, stop-words removal was not necessary, since Legal-BERTimbau, being a version of SBERT, performs better with context rather than with only keywords.
The search system was implemented using Elasticsearch, which allows for scalability and fast retrieval of results while making use of the cosine similarity function to search through embeddings. Elasticsearch was a requirement for this project, as stated in 4.1.1 . Indices require initial mapping where the size of the embeddings needs to be provided as well as other extra information, such as the original document from where the sentence was retrieved from.
After the pre-processing, the next step was generating the embeddings. The sentence embeddings were created by making use of the Legal-SBERTimbau model hosted on the Hugging Face Hub, through the SentenceTransformers Python library.
With the embeddings generated, it is possible to populate the indexes on Elasticsearch through the Elasticsearch Python Client.
In order to retrieve the results of a specific query, that exact query would be transformed into an embedding by Legal-BERTimbau. The system can proceed to search similar sentences by executing the cosine similarity function on Elasticsearch using the query embedding.
The proposed solution architecture:
4.3.2. Hybrid Search System#
This work also developed a more consistent search system version. It developed a Hybrid Search System, combining the potential of lexical search techniques and the reach of large language models.
The architecture is similar to the developed Semantic Search System. The pre-processing and usage of ElasticSearch are equal, and only the retrieval method changes slightly. Instead of yielding the best matches using the cosine similarity metric, it combines the use of BM25 before evaluating the similarity of the embeddings using the cosine similarity metric.
The method retrieves the top 20 results using BM25. Afterwards, it ranks the results using the cosine similarity metric.