Search System Evaluation
6.2. Search System Evaluation#
To evaluate the semantic search system, we required examples of queries and expected results. With such, we would be able to compare if the retrieved results from each query would be expected or not. Unfortunately, such was not available, and it is a complex process, since, to replicate, it requires manual annotation.
Our solution to evaluate the system performance passed through populating an index with sentence embeddings and then, generating queries. Our assumption was that if we create a query based on document x, the retrieved result should be also from document x.
The first step was to populate an ElasticSearch index. Each indexed document would be composed of a text data field, a dense vector data field that contained the sentence embedding, and an indication of the document from where the sentence was retrieved.
The second step was to create the queries. The queries were created from each document corpus. It utilised the LexRank summarization technique, using the original BERTimbau large model, to retrieve the sentence with the highest centrality. The sentences retrieved from this process were used as our initial queries.
We followed by creating the embeddings for each sentence using different versions of our developed model, Legal-BERTimbau, and retrieved the results using the cosine similarity metric. Our comparison baseline was by utilising BM25 search with the same queries.
Furthermore, we intended to explore the full capabilities of what a semantic search system is supposed to achieve: Understand the meaning of a sentence and search from it. To achieve such, we processed all the queries through a GPT3 model, provided by Open AI, with the intent of rewriting the sentences, keeping the same meaning. We gave the GPT3 model the following instruction: “Escreve, resumidamente, numa só frase, por outras palavras para uma criança, em Português: Input: [Query] Output: “, which translates to: “Write, briefly, in one sentence, in other words for a child, in Portuguese: Input: [Query] Output:”. The evaluation architecture is shown:
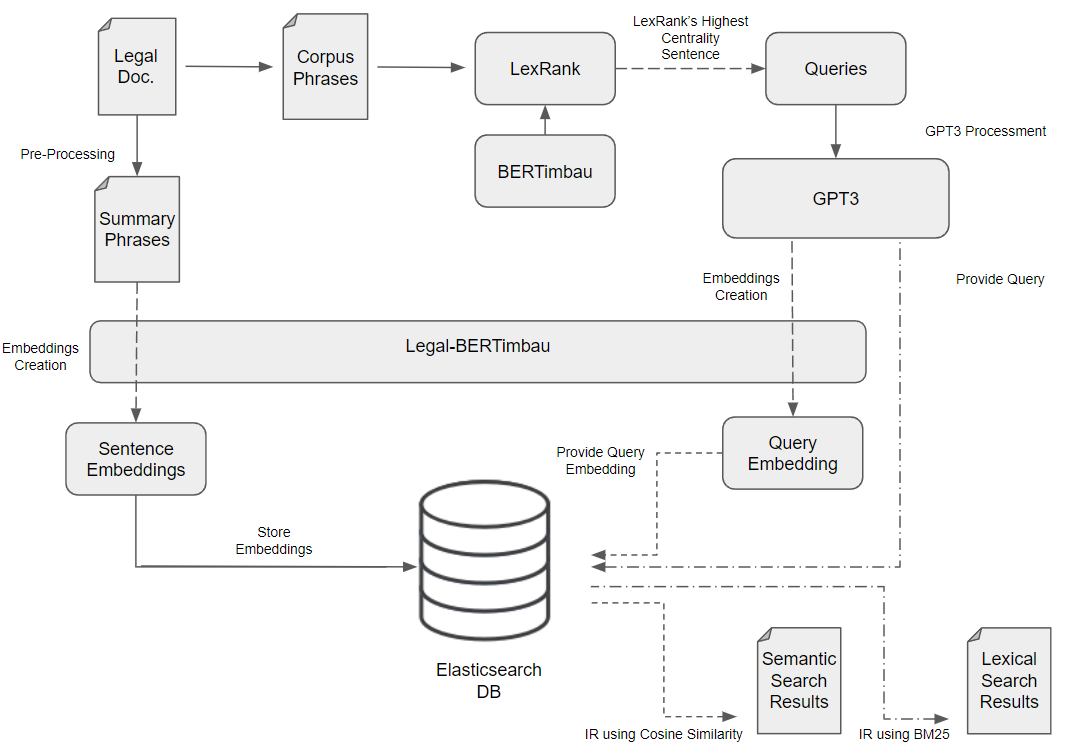
The results displayed in the next tables contains the amount of times the first retrieved result from each query is from the original document as the query itself. Similarly, we also verify, for each query, if a result in the top 5 results come from the original document or not. For each evaluation, we also compared the BM25 performance and BERTimbau original large model.
System Evaluation on Queries generated from the Corpus
Model |
Top 1 |
Top 5 |
|---|---|---|
neuralmind/bert-large-portuguese-cased |
28 |
45 |
BM25 |
48 |
64 |
– |
– |
– |
rufimelo/Legal-BERTimbau-large-TSDAE-sts |
40 |
58 |
rufimelo/Legal-BERTimbau-large-v2-sts |
35 |
49 |
rufimelo/Legal-BERTimbau-sts-base-ma-v3 |
29 |
51 |
rufimelo/Legal-BERTimbau-sts-large-v2 |
41 |
58 |
rufimelo/Legal-BERTimbau-sts-large |
39 |
57 |
rufimelo/Legal-BERTimbau-large-TSDAE-sts-v2 |
38 |
57 |
rufimelo/Legal-BERTimbau-large-TSDAE-sts-v3 |
43 |
66 |
rufimelo/Legal-BERTimbau-large-TSDAE-sts-v4 |
42 |
60 |
System Evaluation on Queries generated from the Corpus processed by GPT3
Model |
Top 1 |
Top 5 |
|---|---|---|
neuralmind/bert-large-portuguese-cased |
33 |
45 |
BM25 |
27 |
46 |
– |
– |
– |
rufimelo/Legal-BERTimbau-large-TSDAE-sts |
34 |
52 |
rufimelo/Legal-BERTimbau-large-v2-sts |
32 |
58 |
rufimelo/Legal-BERTimbau-sts-base-ma-v3 |
27 |
47 |
rufimelo/Legal-BERTimbau-sts-large-v2 |
35 |
60 |
rufimelo/Legal-BERTimbau-sts-large |
30 |
48 |
rufimelo/Legal-BERTimbau-large-TSDAE-sts-v2 |
35 |
55 |
rufimelo/Legal-BERTimbau-large-TSDAE-sts-v3 |
35 |
56 |
rufimelo/Legal-BERTimbau-large-TSDAE-sts-v4 |
31 |
56 |
From the results, we can verify that when utilising queries containing words that are in our indices, BM25 surpasses our semantic search system. Nevertheless, when the queries are re-written in another way, a semantic search system has the capability to outperform a traditional searching method. Furthermore, if we analyse a semantic search system with the BERTimbau model, we can verify its performance is significantly lower than a semantic search system with the models we developed. This outperformance can be shown, especially when comparing the top 5 metric, up to 15%.
Furthermore, we decided to analyse the performance of our semantic search system with queries that are more realistic. Often, in a real use case scenario, users would not write a query as extensive as the ones we have for the previous evaluations. Knowing that processed our GPT3 query in different ways. Using TF-IDF, we retrieved the top 5 keywords for each query and created sub-sentences containing a sequence of 10 words at random from the query. Also, we produced sentences utilising 2 words in the front and in the back of each top 3 keywords in each query, plus the keywords themselves. The results for a semantic search system utilising the model rufimelo/Legal-BERTimbau-sts-large-v2 is shown in following table.
rufimelo/Legal-BERTimbau-sts-large-v2
Query |
Top 1 Sem. |
Top 1 Lex. |
Top 5 Sem. |
Top 5 Lex. |
|---|---|---|---|---|
Original Sentence |
41 |
48 |
58 |
64 |
Top 5 Keywords |
22 |
32 |
44 |
50 |
Synonyms |
39 |
46 |
58 |
64 |
Random Sub-Sentence |
14 |
16 |
31 |
33 |
GPT3 Query |
35 |
27 |
60 |
46 |
GPT3 Top 5 Keywords |
25 |
25 |
41 |
44 |
GPT3 Synonyms |
34 |
26 |
59 |
46 |
GPT3 Random Sub-Sentence |
21 |
18 |
39 |
30 |
GPT3 Sentence from Keywords |
23 |
21 |
45 |
37 |
We can conclude that the semantic search system, expectedly, lowers its performance with smaller queries, since they start to be a group of words instead of a sentence with meaning. Thus, with the model unable to capture the inherent essence of each query, a traditional searching technique such as BM25 surpasses our system. Nevertheless, with smaller queries, containing some inherent meaning (“Random Sub-Sentence” and “Sentence from Keywords”) our semantic search system still performs slightly better than BM25.