Multilingual Sentence Embeddings
3.3. Multilingual Sentence Embeddings#
One issue raised by using pre-trained models is that the embeddings models are usually monolingual, since they are usually trained in English. In 2020, the lead researcher from the team that published SBERT, introduced a technique called multilingual knowledge distillation [RG20]. It relies on the premises that for a set of parallel sentences \(((s_1, t_1), ...,(s_n, t_n))\) with \(t_i\) being the translation of \(s_i\) and a teacher Model \(M\), a Model \(\hat{M}\) would produce vectors for both \(s_i\) and \(t_i\) close to the teacher Model \(M\) sentence vectors. For a given batch of sentences \(\beta\), they minimize the mean-squared loss as follows:
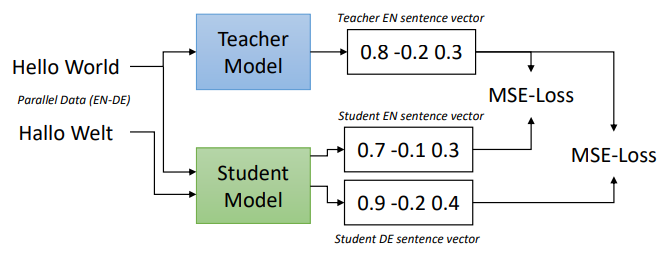
Figure retrieved from [RG20]
Multilingual SBERT versions, such as paraphrase-multilingual-mpnet-base (768 Dimensions) or paraphrase-multilingual-MiniLM-L12 (384 Dimensions) would provide relatively accurate embeddings to this context. The mpnet model, as a larger model than MiniLM, should be able to better comprehend the meaning of a text that it hasn’t explicitly seen before, such as queries with only 1 or 2 words.