Sentence-BERT
3.2. Sentence-BERT#
There was a need for representing an entire sentence in an embedding, instead of only one word or token. One implementation was using the BERT model on all the tokens present in a sentence and producing a mean pooling. Even though this technique was fast enough for the desired problem, it was not very accurate (GloVe embeddings, designed in 2014 produced better results than this technique).
Sentence-BERT (SBERT) [RG19], implemented in 2019 by a group of researchers from the Ubiquitous Knowledge Processing (UKP) lab, is a modification of the BERT network using siamese and triplet networks which can create sentence embeddings that are semantic meaningful. This modification of BERT allows for new types of tasks, such as semantic similarity comparison or information retrieval via semantic search.
Reimers and Gurevych showed that SBERT is dramatically faster than BERT to compare sentence pairs. From 10 000 Sentences it took BERT 65 hours to find the most similar sentence, while SBERT produced the embeddings in approximately 5 seconds and, using the cosine similarity, it took approximately 0.01 seconds.
The siamese architecture is composed of two BERT models that have weights entangled between them. In the training process, the sentences would be fed to both BERT models, which then would go through a pooling operation that would transform the token embeddings of size \(512 \times 768\) into a vector of a fixed size of \(768\).
One way of fine-tuning SBERT is through the Softmax loss approach. It used a combination of the Stanford Natural Language Inference (SNLI) [SNL] and the Multi-Genre NLI [Mul] datasets. The datasets contained pairs of sentences (premises and hypothesis) that could be related through a label feature. This label feature determined whether the sentences are related or not.
“entailment”, the premise suggests the hypothesis
“neutral”, the premise and hypothesis could not be related
“contradiction”, the premise and hypothesis contradict each other
This type of fine-tuning aims to train the model to identify the relationship between sentences.
Another task that SBERT can be fine-tuned is the Semantic Textual Similarity (STS) task. The siamese architecture calculates the cosine similarity between \(u\) and \(v\) sentence embeddings. The researchers also tried negative Manhattan and negative Euclidean distances as similarity measures, but the results were similar. The model performance evaluation, in terms of Semantic Textual Similarity, was evaluated on Supervised and Unsupervised Learning.
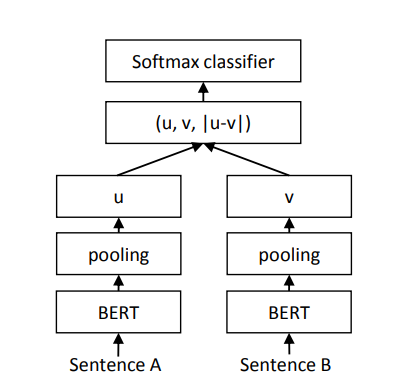
Figure retrieved from [RG19]
Regarding the Unsupervised Learning, the researchers used the STS tasks 2012 – 2016 by Agirre et al. [Agia] [Agib] [Agic] [Agid] [Agie], the STS benchmark by Cer et al. [Cer] and the SICK-Relatedness dataset [Mar]. Each of these three datasets contained gold labels between 0 and 5 that reflects how similar each sentence pair is.
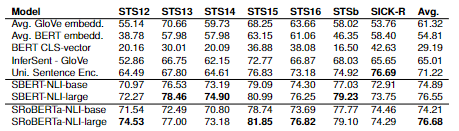
Figure retrieved from [RG19]
To evaluate Supervised learning, the researchers chose to fine-tune \ac{SBERT} only with the \ac{STS} benchmark (STSb), which is “a popular dataset to evaluate supervised \ac{STS} systems” (Reimers et al. 2019) and first train on \ac{NLI} and then on STSb.
To evaluate Supervised learning, the researchers chose to fine-tune SBERT only with the STS benchmark (STSb), which is “a popular dataset to evaluate supervised STS systems” (Reimers et al. 2019) and first train on NLI and then on STSb.
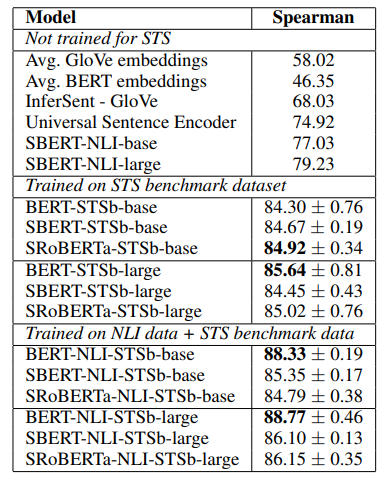
Figure retrieved from [RG19]